「オライリーのebookから空白を除去……」に関する補遺(2) バイナリパッチによる空白の除去 - ただのにっき(2011-03-30)
http://sho.tdiary.net/20110330.html一方、面白い手法の紹介もあった。わいえむねっと - 2011/03/30で紹介されているのは、PDFファイルの「CropBox」指定を直接書き換える方法。バイナリパッチだ! これはいいな(笑)。
ただただし氏に先日のスクリプトを紹介していただいてから、ちょっとした反響がありました。
せっかくなので、
メタデータについても考えてみました。
PDF の仕様について
PDF は元のファイル内容を保持したまま、ファイル末尾に更新内容を追加することでファイル内容を編集することが可能なフォーマットになっています。
今回購入したオライリーの Ebook に限っていえば、そもそもメタデータを持っていないので、単純にメタデータのオブジェクトを追加してやればよさそうです。
なお、更新内容を追加するには、オブジェクト以外に
が必要になります。
暗号化ついて
オライリーの Ebook は 40-bit RC4 で暗号化されています。(パスワードは空ですが)
追加するオブジェクトも暗号化する必要があります。
暗号化の手順については、
を参考にしました。
格納する情報について
Amazon API で取得しようかと思ったら、
オライリー自身が提供してくれていたので利用してみました。
スクリプト
例によって Perl です。
use strict;
use warnings;
use Crypt::RC4;
use Digest::MD5;
use Encode;
use JSON;
use LWP::UserAgent;
undef $/;
my $pass = '';
my $url = 'http://www.oreilly.co.jp/books/%s/biblio.json';
my $ua = LWP::UserAgent->new;
while(<*.pdf>)
{
next unless /-(\d{13})/;
my $bookinfo = get_bookinfo($1);
open my $in, $_ or die;
open my $out, '>', $bookinfo->{title}.'.pdf' or die;
binmode $in;
binmode $out;
$_ = <$in>;
my $len = length;
my($owner, $perm, $trailer, $prev);
$owner = $1 while /\/O\s*\((.+?)\)/gs;
$perm = $1 while /\/P\s+(-?\d+)/g;
$trailer = $1 while /(trailer\n<<.+?>>)/gs;
$prev = $1 while /startxref\n(\d+)/g;
die unless $trailer;
die unless $prev;
die unless $owner;
die unless $perm;
$trailer =~ /<(.+?)>/;
my $id = $1;
$trailer =~ /\/Size (\d+)/;
my $info = $1;
my $filekey = generate_filekey($pass, $owner, $perm, $id);
my $key = generate_key($filekey, $info, 0);
my $title = RC4($key, $bookinfo->{original});
my $author = RC4($key, $bookinfo->{authors});
escape($title);
escape($author);
my $obj = <<EOS;
$info 0 obj
<<
/Title ($title)
/Author ($author)
>>
endobj
EOS
my $size = $info + 1;
$trailer =~ s/(\/Size\s+)\d+/$1$size/;
$trailer =~ s/(>>)/\/Prev $prev \/Info $info 0 R $1/;
my $offset = sprintf '%010d', $len;
my $startxref = $len + length $obj;
my $xref = <<EOS;
xref
$info 1
$offset 00000 n
$trailer
startxref
$startxref
%%EOF
EOS
print $out $_;
print $out $obj;
print $out $xref;
}
sub get_bookinfo
{
my $req = HTTP::Request->new(GET => sprintf $url, $1);
my $res = $ua->request($req);
$res->is_success or die $res->status_line;
my $bookinfo = decode_json $res->content;
exists $bookinfo->{title} or die;
exists $bookinfo->{authors} or die;
exists $bookinfo->{original} or die;
$bookinfo->{title} =~ s/[:\/\\]/ /g;
$bookinfo->{title} =~ s/\s+/ /g;
utf8::encode $bookinfo->{title};
Encode::from_to $bookinfo->{title}, 'utf8', 'shiftjis';
my @authors;
foreach(@{$bookinfo->{authors}})
{
foreach(split /\,/, $_)
{
next unless /[a-zA-Z]/;
s/[^\x20-\x7E]//g;
s/^\s*(.*?)\s*$/$1/;
push @authors, $_;
}
}
$bookinfo->{authors} = join ', ', @authors;
$bookinfo->{original} =~ s/[^\x20-\x7E]+//g;
return $bookinfo;
}
sub generate_filekey
{
my $pad = pack 'H*',
'28BF4E5E4E758A4164004E56FFFA0108'.
'2E2E00B6D0683E802F0CA9FE6453697A';
my $md5 = Digest::MD5->new;
$md5->add(substr $_[0].$pad, 0, 32);
$md5->add($_[1]);
$md5->add(pack 'V', $_[2]);
$md5->add(pack 'H*', $_[3]);
substr $md5->digest, 0, 5;
}
sub generate_key
{
my $md5 = Digest::MD5->new;
$md5->add($_[0]);
$md5->add(substr pack('V', $_[1]), 0, 3);
$md5->add(substr pack('V', $_[2]), 0, 2);
substr $md5->digest, 0, 10;
}
sub escape
{
$_[0] =~ s/\\/\\\\/g;
$_[0] =~ s/\n/\\n/g;
$_[0] =~ s/\r/\\r/g;
$_[0] =~ s/\t/\\t/g;
$_[0] =~ s/\f/\\f/g;
$_[0] =~ s/\(/\\(/g;
$_[0] =~ s/\)/\\)/g;
}
おおまかな処理の流れ
- ファイル名からISBNを抽出し、書籍情報を取得
- ファイルから更新内容の追加に必要な情報を抽出
- メタデータオブジェクトを作成して、暗号化した書籍情報を格納
- クロスリファレンステーブルとファイルトレーラを作成
- 書籍名でファイルを複製
- メタデータを追加
実行結果
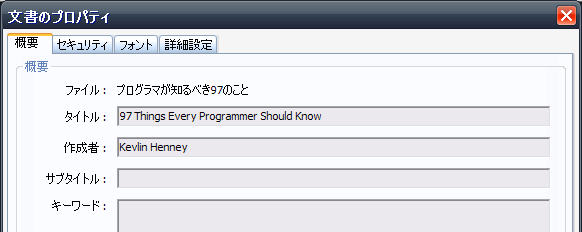
できました!
既知の問題とか制限事項とか
あくまで、「今回自分が購入した6冊が Adobe Reader に怒られない」ようにした程度の実装なので、いろいろいい加減です。
- 既存のメタデータがある場合を考慮していない
- /O や /P の検索がいい加減
- /Encrypt で指定したオブジェクトから取得するようにするべき
- 追加データの /ID を更新していない
暗号化時に「Adobe Reader が誤認しなさそうな結果が得られるまで、シードを変えて繰り返す」とかいう日和ったことをしている
- 「あんまりだ」と言われたので、エスケープ処理を追加
などなど。
雑感
さすがに前回ほど簡潔にはなりませんでした。
書籍情報取得のあたりは含めないほうがよかったかなと後悔。
あと、DRM の解除をしているわけではありませんが、パスワードが分かっていることを前提としているので、行為的には DRM の解除と大して変わらないです。微妙。
まぁ、こんなこともできなくはない的な実験として。

 2011/04/03 04:54:00
2011/04/03 04:54:00