- 2011/04/05 Tue
-
別アプリケーションの打ち合わせに呼ばれていってみたりとか、
DB2のホストで一騒動あったので首を突っ込んできてみたりとか、
隣の隣の島の関係ないチームの人と話してきたりとか、
なんでも屋みたいになってる人にお願い事をしにいったりとか、
本来の仕事したりとか。
どう見ても花粉症なのに花粉症じゃないと言い張り続けていた人が今日はマスクをつけていたので「ついに認めたんですか?」と聞いたら「いや、風邪」と返ってきたのでまたまたーと思っていたのですが、気が付いたら自分も体の節々が痛くなったり寒気がしたりしてきました。
うつったのかこれ。
とりあえず早めのパブロン。
 2011/04/05 23:31:55
2011/04/05 23:31:55
- 2011/04/04 Mon
-
久し振りにコートなしで出社。
マフラーくらいしていくかとも思ったけれど、それもなしで。
帰りは多少寒かったですが、そんなに寒いわけでもなく。
しばらくこれくらいの気候が続いてくれたらなと思う程度。2011/04/05 00:59:19
- 2011/04/03 Sun
-
「オライリーのebookから空白を除去……」に関する補遺(2) バイナリパッチによる空白の除去 - ただのにっき(2011-03-30)
http://sho.tdiary.net/20110330.html一方、面白い手法の紹介もあった。わいえむねっと - 2011/03/30で紹介されているのは、PDFファイルの「CropBox」指定を直接書き換える方法。バイナリパッチだ! これはいいな(笑)。
ただただし氏に先日のスクリプトを紹介していただいてから、ちょっとした反響がありました。
せっかくなので、あー、いや、メタ情報の問題が残ってるか。ううむ。
メタデータについても考えてみました。PDF の仕様について
PDF は元のファイル内容を保持したまま、ファイル末尾に更新内容を追加することでファイル内容を編集することが可能なフォーマットになっています。
今回購入したオライリーの Ebook に限っていえば、そもそもメタデータを持っていないので、単純にメタデータのオブジェクトを追加してやればよさそうです。
なお、更新内容を追加するには、オブジェクト以外に- クロスリファレンステーブル
- ファイルトレーラ
が必要になります。暗号化ついて
オライリーの Ebook は 40-bit RC4 で暗号化されています。(パスワードは空ですが)
追加するオブジェクトも暗号化する必要があります。
暗号化の手順については、PDF protection - SCHOOL OF COMPUTER SCIENCE, Carnegie Mellon
http://www.cs.cmu.edu/~dst/Adobe/Gallery/anon21jul01-pdf-encryption.txt
を参考にしました。格納する情報について
Amazon API で取得しようかと思ったら、JSON形式による書誌情報の提供をはじめました - O'Reilly Japan Community Blog
http://www.oreilly.co.jp/community/blog/2010/11/bibliographical-info-in-json.html以前は手作業でファイル名を変更していたのですが、100タイトルを超えた辺りで心が折れました。Amazon APIを使って書名を取得すればいいことは分かっていたのですが、発行元がそれをしてしまったら負けな気がします。
そこでWebサイトの書誌情報を以下のようなURLで取得できるように、テンプレートを1つ追加しました。ファイル名をご覧いただくと分かるように、簡単な書誌情報をJSON形式でご提供しています。
オライリー自身が提供してくれていたので利用してみました。スクリプト
例によって Perl です。use strict; use warnings; use Crypt::RC4; use Digest::MD5; use Encode; use JSON; use LWP::UserAgent; undef $/; my $pass = ''; my $url = 'http://www.oreilly.co.jp/books/%s/biblio.json'; my $ua = LWP::UserAgent->new; while(<*.pdf>) { next unless /-(\d{13})/; my $bookinfo = get_bookinfo($1); open my $in, $_ or die; open my $out, '>', $bookinfo->{title}.'.pdf' or die; binmode $in; binmode $out; $_ = <$in>; my $len = length; my($owner, $perm, $trailer, $prev); $owner = $1 while /\/O\s*\((.+?)\)/gs; $perm = $1 while /\/P\s+(-?\d+)/g; $trailer = $1 while /(trailer\n<<.+?>>)/gs; $prev = $1 while /startxref\n(\d+)/g; die unless $trailer; die unless $prev; die unless $owner; die unless $perm; $trailer =~ /<(.+?)>/; my $id = $1; $trailer =~ /\/Size (\d+)/; my $info = $1; my $filekey = generate_filekey($pass, $owner, $perm, $id); my $key = generate_key($filekey, $info, 0); my $title = RC4($key, $bookinfo->{original}); my $author = RC4($key, $bookinfo->{authors}); escape($title); escape($author); my $obj = <<EOS; $info 0 obj << /Title ($title) /Author ($author) >> endobj EOS my $size = $info + 1; $trailer =~ s/(\/Size\s+)\d+/$1$size/; $trailer =~ s/(>>)/\/Prev $prev \/Info $info 0 R $1/; my $offset = sprintf '%010d', $len; my $startxref = $len + length $obj; my $xref = <<EOS; xref $info 1 $offset 00000 n $trailer startxref $startxref %%EOF EOS print $out $_; print $out $obj; print $out $xref; } sub get_bookinfo { my $req = HTTP::Request->new(GET => sprintf $url, $1); my $res = $ua->request($req); $res->is_success or die $res->status_line; my $bookinfo = decode_json $res->content; exists $bookinfo->{title} or die; exists $bookinfo->{authors} or die; exists $bookinfo->{original} or die; $bookinfo->{title} =~ s/[:\/\\]/ /g; $bookinfo->{title} =~ s/\s+/ /g; utf8::encode $bookinfo->{title}; Encode::from_to $bookinfo->{title}, 'utf8', 'shiftjis'; my @authors; foreach(@{$bookinfo->{authors}}) { foreach(split /\,/, $_) { next unless /[a-zA-Z]/; s/[^\x20-\x7E]//g; s/^\s*(.*?)\s*$/$1/; push @authors, $_; } } $bookinfo->{authors} = join ', ', @authors; $bookinfo->{original} =~ s/[^\x20-\x7E]+//g; return $bookinfo; } sub generate_filekey { my $pad = pack 'H*', '28BF4E5E4E758A4164004E56FFFA0108'. '2E2E00B6D0683E802F0CA9FE6453697A'; my $md5 = Digest::MD5->new; $md5->add(substr $_[0].$pad, 0, 32); $md5->add($_[1]); $md5->add(pack 'V', $_[2]); $md5->add(pack 'H*', $_[3]); substr $md5->digest, 0, 5; } sub generate_key { my $md5 = Digest::MD5->new; $md5->add($_[0]); $md5->add(substr pack('V', $_[1]), 0, 3); $md5->add(substr pack('V', $_[2]), 0, 2); substr $md5->digest, 0, 10; } sub escape { $_[0] =~ s/\\/\\\\/g; $_[0] =~ s/\n/\\n/g; $_[0] =~ s/\r/\\r/g; $_[0] =~ s/\t/\\t/g; $_[0] =~ s/\f/\\f/g; $_[0] =~ s/\(/\\(/g; $_[0] =~ s/\)/\\)/g; }おおまかな処理の流れ
- ファイル名からISBNを抽出し、書籍情報を取得
- ファイルから更新内容の追加に必要な情報を抽出
- メタデータオブジェクトを作成して、暗号化した書籍情報を格納
- クロスリファレンステーブルとファイルトレーラを作成
- 書籍名でファイルを複製
- メタデータを追加
実行結果
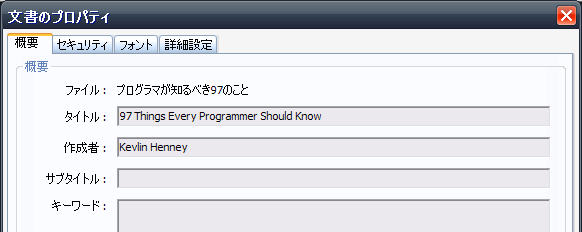
できました!既知の問題とか制限事項とか
あくまで、「今回自分が購入した6冊が Adobe Reader に怒られない」ようにした程度の実装なので、いろいろいい加減です。- 既存のメタデータがある場合を考慮していない
- /O や /P の検索がいい加減
- /Encrypt で指定したオブジェクトから取得するようにするべき
- 追加データの /ID を更新していない
暗号化時に「Adobe Reader が誤認しなさそうな結果が得られるまで、シードを変えて繰り返す」とかいう日和ったことをしている
- 「あんまりだ」と言われたので、エスケープ処理を追加
- 全角文字は非対応
- データ構成が別物になるようなので。なんでだ。
などなど。雑感
さすがに前回ほど簡潔にはなりませんでした。
書籍情報取得のあたりは含めないほうがよかったかなと後悔。
あと、DRM の解除をしているわけではありませんが、パスワードが分かっていることを前提としているので、行為的には DRM の解除と大して変わらないです。微妙。
まぁ、こんなこともできなくはない的な実験として。2011/04/03 04:54:00
- Comments
-
> 書籍情報の取得を切り出すなど、ちょと修正。
- 2011/04/02 Sat
-
新入社員の歓迎会があったとかで社長から呼び出されていってきてみたら、「歓迎会があった」後のことで新入社員とかは特に関係ない食事会でした。なんなの。
2011/04/03 04:50:26
- 2011/04/01 Fri
-
新年度ですか。
人が猛烈に少ないのは、昨日までが契約期間だった人が軒並みはけたからなのか、昨日が年度末ゆえに昨年度の鬱憤が発散されてきた結果ゆえかは神のみぞ知るところかと思いつつ、仕事をしたり仕事とは関係のないコードを書いてみたり。2011/04/02 20:37:48
- 2011/03/31 Thu
-
年度末ですね。
本日で終了の方が自分のチームに1名、隣のチームに3名おられたので、合同で送別会がありました。
せっかく隣のチームと合同なわけですしと、隣のテーブルまでビール片手にちょいと根回ししにいってみたりとか。
明日は金曜日とかお構いなしに飲んでみたりとか。
というか、自分も今日までだったはずなんですけどね。
前回に続いてまた延長になったので、もう少しだけシーサイドのようです。
ぼちぼち自社のほうから呼び戻しの声が掛かっているので、いつまでになることやら。2011/04/01 01:05:52
- 2011/03/30 Wed
-
オライリーのebookから余白を除去して、Kindleで快適に読む方法 - ただのにっき(2011-03-28)
http://sho.tdiary.net/20110328.html#p01電子書籍端末向けにPDFを加工するには、テキストデータを抽出する方法や、PDFをそのまま加工(crop)する方法があるが、オライリーのPDFはDRMがかかっているのでいずれもうまくいかないようだ。
歯を磨きながら Ebook のバイナリをぼけと眺めてみたのですが、CropBox の書き換えは特に問題なさそうな気がしたので試してみました。スクリプト
例によって Perl で。use strict; use warnings; # left, bottom, right, top my @offset = (20, 20, -20, -20); while(<*.pdf>) { next if /-cropped/; open my $in, $_ or die; s/(.*)(\.pdf)$/$1-cropped$2/; open my $out, '>', $_ or die; binmode $in; binmode $out; while(<$in>) { s/(\/CropBox\s*\[\s*([^\[]+)\])/crop($1, $2)/eg; print $out $_; } } sub crop { my @offset = @offset; my @pos = map{int $_ + shift @offset} split /\s+/, $_[1]; my $crop = sprintf '/CropBox[%d %d %d %d]', @pos; my $blank = length($_[0]) - length $crop; warn $_[0] and return $_[0] if $blank < 0; return $crop.(' ' x $blank); }実行結果
CropBox 変更前

CropBox 変更後

やったね!
# 写真のはかなりカツカツに設定してます。(60, 43, -60, -74)味噌
/CropBox [ 0 0 516 659.52 ]
を/CropBox [ 20 20 496 639.52 ]
のように加工するとオフセットが破綻してファイルが壊れるため、小数点以下を捨てたりスペースを除去して桁を増やすための領域を無理やり確保しています。
まぁ、簡易処置ということで。
当然、領域が確保できない場合も想定されるわけですが、その場合は警告を出力して、その位置の CropBox は無視します。
今回自分が購入した(うちのURLが届いた分)5冊については、警告なしで通ったのでとりあえず良し。
ThoughtWorksアンソロジーのサンプル3種についても試してみましたが、警告なしで通りました。O'Reilly Japan - ThoughtWorksアンソロジー
http://www.oreilly.co.jp/books/9784873113890/
寝よう。 2011/03/30 02:42:41
2011/03/30 02:42:41
- 2011/03/29 Tue
-
滑り込みで購入した分のダウンロードURLがまだ届かない。
と思ってたら、待ち時間の案内がでてた。O'Reilly Japan Ebook Store ダウンロードURLご案内までの待ち時間
http://www.oreilly.co.jp/ebook/ebook-stat.htmlただいま多くのご注文をいただいて、処理が大幅に遅延しており、ご注文からダウン>ロードURLのお知らせまで
約50時間
お時間をいただいております。
現在
2011-03-25T20:09:04
までにご注文頂いたPDFのダウンロードURLをご案内しています。
はい。まだですね!Referer:2011/03/29 07:18:39
帰宅して、まず確認。2011/03/29 23:05:23
O'Reilly Japan Ebook Store ダウンロードURLご案内までの待ち時間
http://www.oreilly.co.jp/ebook/ebook-stat.htmlただいま多くのご注文をいただいて、処理が大幅に遅延しており、ご注文からダウンロードURLのお知らせまで
約34時間
お時間をいただいております。
現在
2011-03-25T22:08:22
までにご注文頂いたPDFのダウンロードURLをご案内しています。
16時間経過して、2時間分進行。
この時間内だけで、どれだけ注文されてたんだって話ですよ。
そして、その倍以上、最後の2時間に注文されているわけで。先はまだ長い。2011/03/29 22:57:57
- 2011/03/28 Mon
-
ここ最近、社食のサイドメニューで冷奴がでません。
今日に至っては、「冷奴は相変わらずないけど、今日は麻婆豆腐だ!わー!」と思ったら、麻婆大根でした。
泣いた。滑り込みで購入した分のダウンロードURLがまだ届かない。2011/03/29 00:51:21
2011/03/29 00:51:25
- 2011/03/27 Sun
-
昨日までのあらすじ:オライリーの Ebook をまとめて買ったので、電子ブックリーダーの購入を検討をしたよ。
今日のあらすじ:電子ブックリーダーを買ってきたよ。
はい。
Kindle は触ったことあるけど Reader はないので、とりあえず触りにいかないとねと触りにいった帰りに、気が付いたら Reader をお持ち帰りしてました。PRS-650。
標準で入っている使用許諾契約書が都合よく pdf で横表示の挙動を確認できたのと、実際に Reader の横表示を片手操作してみて、やっぱり Kindle のボタン配置は片手操作むずかしいなと思ったのとで。
うっかり。
横表示なんですが、PRS-650 と PRS-350 とで回転方向が逆なんですね。なんでなんだぜ?
ちなみに、PRS-650 だとボタンが左側。
帰宅するなり早速 pdf を突っ込んでみたのですが、最初の感想は「うっかり5インチを買わなくて正解だったな!」ということでした。
PRS-350 の実機を触ってみて、5インチでもいけるか…?と思わないでもなかったのですが、踏みとどまって正解でした。主に文字サイズ的な意味で。
6インチも十分軽いし、自分には PRS-650 がバランスとれてそうです。
これから通勤時にぬるぬる活用していきたい!2011/03/29 00:30:28